The Web is a Minefield: How Hidden “Agent Traps” Can Hijack Autonomous AI
Researchers from Google DeepMind have elucidated how mundane web pages can be transmuted into instruments of assault against autonomous AI agents. This phenomenon pertains not to the sophisticated breaching of infrastructure, but to the meticulous crafting of content designed to obfuscate algorithms and coerce them into serving the interests of an adversary.
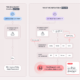
In their published discourse, the team delineates six distinct taxonomies of attack that exploit website content to manipulate context and provoke erratic behaviors. These scenarios, designated as “AI Agent Traps,” may be utilized by malicious actors for clandestine product promotion, data exfiltration, or the mass dissemination of propaganda.
The authors clarify that malicious elements are embedded directly within web pages or digital assets, preying upon the behavioral nuances of agents—such as their adherence to instructions, utilization of tools, and prioritization of tasks. Consequently, even a fastidiously configured agent may interpret hidden directives as legitimate mandates.
The identified classes of attack encompass the injection of concealed content, semantic manipulation, interference with an agent’s “cognitive state,” behavioral coercion, systemic vulnerabilities, and human-integrated scenarios. In many instances, the exploit capitalizes on the discrepancy between human perception and machine analysis; for example, directives may be secreted within HTML comments, metadata, or subtle text formatting.
A specialized vector involves semantic snares, where phrasing is meticulously selected to induce bias in the agent or circumvent verification mechanisms. Another class of attack targets long-term memory by infiltrating external sources or internal logs with deleterious data, causing the agent to rely upon distorted information.
Behavioral control scenarios include bypassing constraints through external resources, compelling the disclosure of confidential data, and even the unauthorized spawning of subordinate agents that inherit the same privileges but serve the attacker’s agenda. Systemic incursions exploit the interaction among multiple agents, leveraging the synchronicity and inherent trust within the network.
Of particular concern are situations involving human interaction, where research indicates that hidden commands can force an agent to dispense harmful instructions disguised as recommendations, including scenarios reminiscent of ransomware behavior.
The team emphasizes that the mitigation of such threats is hindered by three factors: the complexity of detection, the difficulty of attribution, and the necessity for rapid adaptation to novel techniques. Proposed countermeasures include fortifying models through specialized fine-tuning, implementing runtime protections, and developing robust content governance policies alongside unified risk assessment standards. The authors contend that shielding AI agents from environmental manipulation is a fundamental imperative for the industry; without the collective efforts of developers, security experts, and regulators, the realization of a reliable ecosystem for autonomous systems will remain elusive.
Support Our Threat Intelligence
If you find our technology report and cybersecurity news helpful, consider supporting our work.