Waymo introduces LINGO-1, an open-loop driving commentator
Waymo has recently unveiled a pioneering technique, employing a sophisticated integration of large-scale natural language models, allowing its autonomous driving system to elucidate its vehicular navigation methodologies.

According to the elucidation, Waymo harnesses a model christened LINGO-1, empowering the autonomous driving system to articulate descriptions of the vanguard roadway conditions perceived through computer vision. Concurrently, it can elucidate decisions made during vehicle transit, offering a profound insight into the modus operandi of the autonomous system, whilst also facilitating rectifications in instances of erroneous judgment.
LINGO-1 operates on the bedrock of Vision-Language-Action Models (VLAMs), which capacitates the autonomous system to parse and comprehend visual feeds captured by cameras, and then enunciate this understanding via natural language, even explicating the rationale behind specific decisions. This enables human overseers to corroborate the accuracy of the system’s determinations.
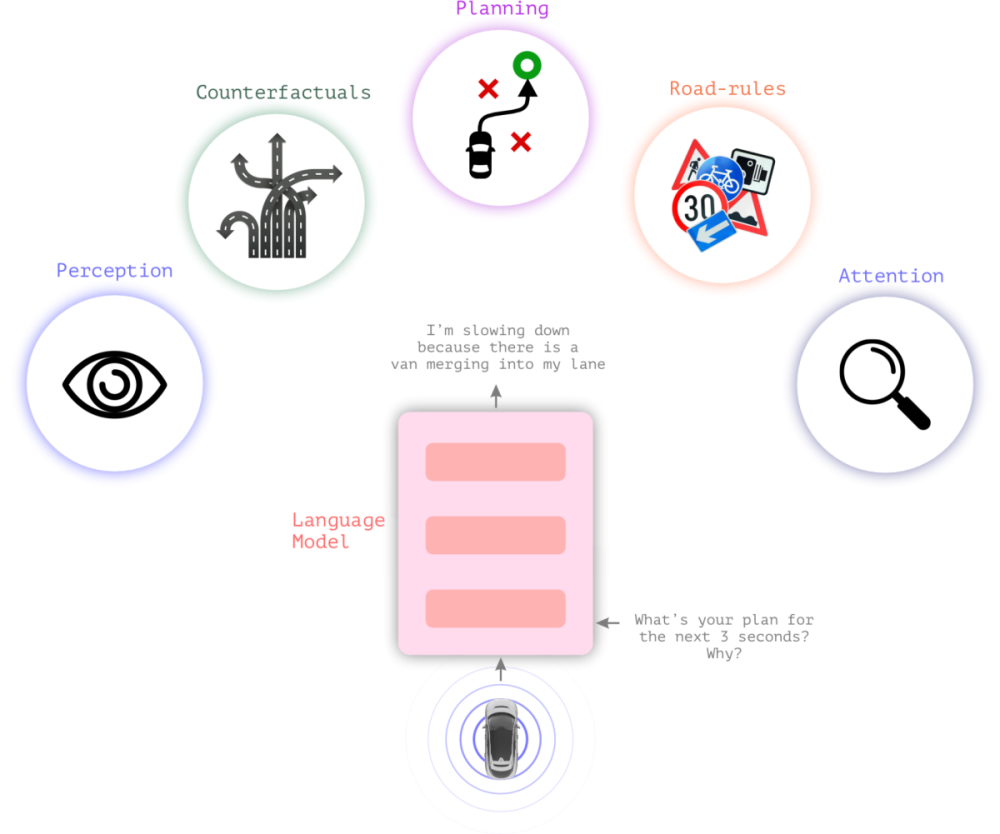
In juxtaposition with yesteryears, where analysts had to decipher why an autonomous driving system might have committed a fallacious decision, leveraging artificial intelligence to proactively narrate its evaluative criteria simplifies the appraisal of the system’s efficacy.
Moreover, beyond enabling the autonomous system to verbalize its operational paradigms, the LINGO-1 model inversely facilitates the training of the driving system via natural language. For instance, guiding the autonomous system through organic dialogues, such as advising against certain driving maneuvers, ensures the system assimilates the essence of the conversation, thereby augmenting its experiential learning.
Per Waymo’s recent evaluations, utilizing natural language as a pedagogical medium has, within a mere month, escalated the accuracy rate of the autonomous system from an erstwhile subpar 30%—lagging behind human performance—to an impressive proximity of 60%. Consequently, this approach could transcend vehicular realms and be harnessed for training robotic apparatuses, significantly amplifying training efficiency and precision.




