SQLAlchemy v1.3.23 released, Python ORM framework
SQLAlchemy is a Python SQL toolkit and a database object mapping framework. It includes a complete enterprise-class persistence model, specifically for efficient and high-performance database access.
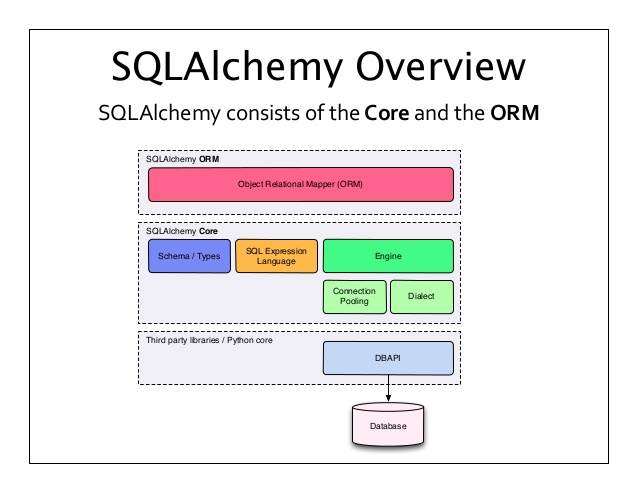
SQL databases behave less like object collections the more size and performance start to matter; object collections behave less like tables and rows the more abstraction starts to matter. SQLAlchemy aims to accommodate both of these principles.
SQLAlchemy considers the database to be a relational algebra engine, not just a collection of tables. Rows can be selected from not only tables but also joins and other select statements; any of these units can be composed into a larger structure. SQLAlchemy’s expression language builds on this concept from its core.
SQLAlchemy is most famous for its object-relational mapper (ORM), an optional component that provides the data mapper pattern, where classes can be mapped to the database in open ended, multiple ways – allowing the object model and database schema to develop in a cleanly decoupled way from the beginning.
SQLAlchemy’s overall approach to these problems is entirely different from that of most other SQL / ORM tools, rooted in a so-called complimentarity- oriented approach; instead of hiding away SQL and object relational details behind a wall of automation, all processes are fully exposed within a series of composable, transparent tools. The library takes on the job of automating redundant tasks while the developer remains in control of how the database is organized and how SQL is constructed.
The main goal of SQLAlchemy is to change the way you think about databases and SQL!
SQLAlchemy v1.3.23 has been released, this release contains various fixes.
Changelog
sql
[sql] [bug]
Fixed bug where making use of the
TypeEngine.with_variant()method on aTypeDecoratortype would fail to take into account the dialect-specific mappings in use, due to a rule inTypeDecoratorthat was instead attempting to check for chains ofTypeDecoratorinstances.References: #5816
postgresql
[postgresql] [bug]
For SQLAlchemy 1.3 only, setup.py pins pg8000 to a version lower than 1.16.6. Version 1.16.6 and above is supported by SQLAlchemy 1.4. Pull request courtesy Giuseppe Lumia.
References: #5645
[postgresql] [bug]
Fixed issue where using
Table.to_metadata()(calledTable.tometadata()in 1.3) in conjunction with a PostgreSQLExcludeConstraintthat made use of ad-hoc column expressions would fail to copy correctly.References: #5850
mysql
[mysql] [usecase]
Casting to
FLOATis now supported in MySQL >= (8, 0, 17) and MariaDb >= (10, 4, 5).References: #5808
[mysql] [bug] [reflection]
Fixed bug where MySQL server default reflection would fail for numeric values with a negation symbol present.
References: #5860
[mysql] [bug]
Fixed long-lived bug in MySQL dialect where the maximum identifier length of 255 was too long for names of all types of constraints, not just indexes, all of which have a size limit of 64. As metadata naming conventions can create too-long names in this area, apply the limit to the identifier generator within the DDL compiler.
References: #5898
[mysql] [bug]
Fixed deprecation warnings that arose as a result of the release of PyMySQL 1.0, including deprecation warnings for the “db” and “passwd” parameters now replaced with “database” and “password”.
References: #5821
[mysql] [bug]
Fixed regression from SQLAlchemy 1.3.20 caused by the fix for #5462 which adds double-parenthesis for MySQL functional expressions in indexes, as is required by the backend, this inadvertently extended to include arbitrary
text()expressions as well as Alembic’s internal textual component, which are required by Alembic for arbitrary index expressions which don’t imply double parenthesis. The check has been narrowed to include only binary/ unary/functional expressions directly.References: #5800
oracle
[oracle] [bug]
Fixed regression in Oracle dialect introduced by #4894 in SQLAlchemy 1.3.11 where use of a SQL expression in RETURNING for an UPDATE would fail to compile, due to a check for “server_default” when an arbitrary SQL expression is not a column.
References: #5813
[oracle] [bug]
Fixed bug in Oracle dialect where retriving a CLOB/BLOB column via
Insert.returning()would fail as the LOB value would need to be read when returned; additionally, repaired support for retrieval of Unicode values via RETURNING under Python 2.References: #5812
misc
[bug] [ext]
Fixed issue where the stringification that is sometimes called when attempting to generate the “key” for the
.ccollection on a selectable would fail if the column were an unlabeled custom SQL construct using thesqlalchemy.ext.compilerextension, and did not provide a default compilation form; while this seems like an unusual case, it can get invoked for some ORM scenarios such as when the expression is used in an “order by” in combination with joined eager loading. The issue is that the lack of a default compiler function was raisingCompileErrorand notUnsupportedCompilationError.References: #5836





