Facebook announces open source wav2letter++, the fastest state-of-the-art speech system
Recently, the Facebook AI Research (FAIR) announced the first full-convergence speech recognition toolkit wav2letter++. The system performs speech recognition based on the full convolution method, and the speed of training speech recognition end-to-end neural network is more than twice that of other frameworks. They gave a detailed introduction to this open source in the blog.
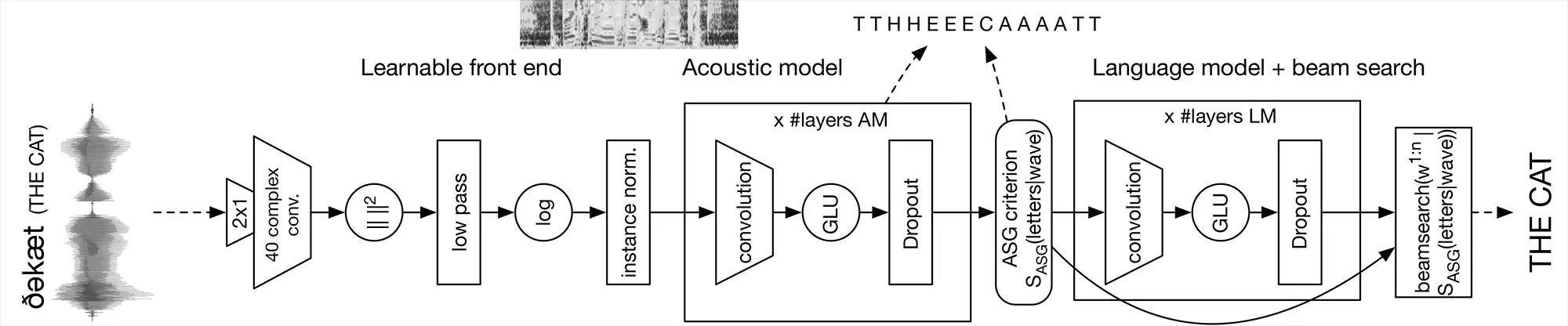
Since end-to-end speech recognition technology can be easily extended to multiple languages and at the same time guarantees recognition quality in a variety of environments, it is generally considered to be an efficient and stable speech recognition technology. Although recursive convolutional neural networks are dominant in dealing with modelling tasks with remote dependencies, such as language modelling, machine translation, and speech synthesis, loop architecture is the mainstream in the end-to-end speech recognition task.
In view of this, the voice team of the Facebook Artificial Intelligence Institute (FAIR) launched the first full-convolution speech recognition system last week. The system consists entirely of convolutional layers, eliminating the feature extraction step and training end-to-end audio only. The transcribed text in the waveform is predicted, and the text is decoded by the external convolution language model. Then Facebook announced the open source wav2letter ++ – the emergence of this high-performance framework, enabling end-to-end speech recognition technology to achieve rapid iteration, laying a solid foundation for future optimization work and model tuning.
Announced open source with wav2letter++, as well as the machine learning library Flashlight. Flashlight is a C++-based machine learning library that uses the ArrayFire tensor library and is compiled in real time in C++ with the goal of maximizing the efficiency and scale of the CPU and GPU backends. The wave2letter ++ toolkit is built on the Flashlight foundation. On top, it is also written in C++, with ArrayFire as the tensor library.
This section focuses on ArrayFire, which can be executed on a variety of backends supported by CUDA GPUs and CPUs, supports multiple audio file formats (such as wav, flac, etc.), and supports multiple types of functions, including raw audio. Linear scaling power spectrum, log mel spectrum (MFSC) and MFCCs.
Project address:
https://github.com/facebookresearch/wav2letter/





