AMD RDNA 3 architecture diagram is exposed, Including Navi 31, Navi 32 and Navi33
Recently, there is a lot of news about AMD’s next-generation RDNA 3 architecture and Navi 3x core. Previous news indicated that Radeon RX 7900 XT is likely to be equipped with Navi 31 and manufactured using a 5nm process. At the same time, Navi 31 will use an MCM multi-chip package, with 240 CUs, that is 15,360 stream processors, Infinity Cache is 512MB, and the video memory bit width is still maintained at 256 bits, still GDDR6. It is rumored that Infinity Cache will be added to the MCD chiplet, similar to the principle of using 3D V-Cache on the Zen 3 architecture, and manufactured using a 6nm process.
AMD will change the original structure instead of the original CU computing unit and will use WGP as the main computing module. Each computing chip in the Navi 31 core will have 30 WGPs, and each WGP will have 256 stream processors. This means that each computing chip can provide 7680 stream processors, so a Navi 31 core will reach the scale of 15,360 stream processors.
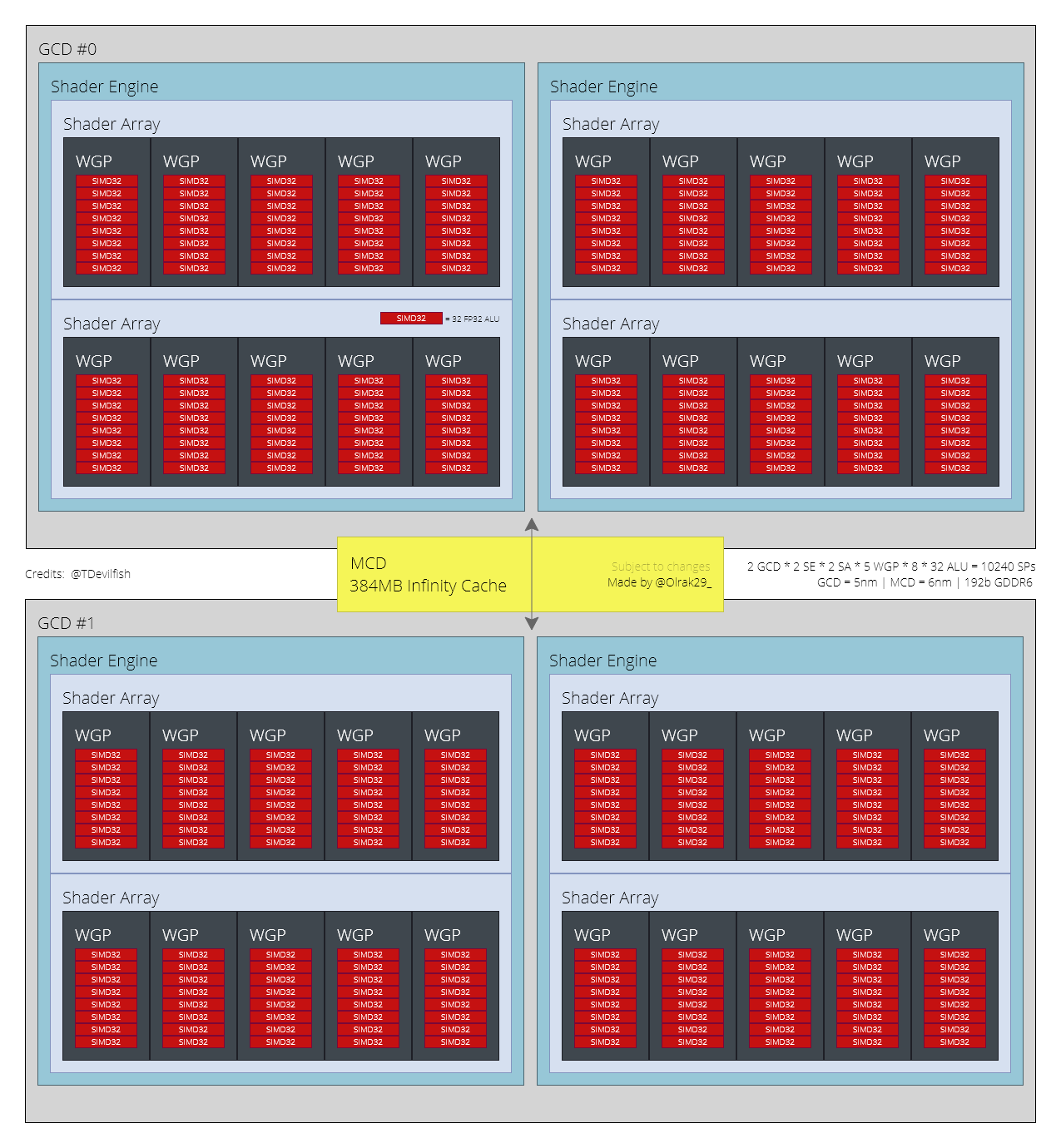
Credit: @TDevilfish
Recently, Twitter user @Olrak29_ provided an architectural diagram of the RDNA 3 architecture, including three GPUs of Navi 31, Navi 32, and Navi 33. Among them, Navi 31 and Navi 32 will use MCM multi-chip packages. Navi 32 has 10240 stream processors, Infinity Cache is 256 or 384MB, and the video memory width is 192 bits. The specifications of Navi 33 are similar to the current Navi 21. There will be 5120 stream processors, Infinity Cache is 128 or 256MB, and the video memory width is 128 bits.
It is understood that GPUs based on the RDNA 3 architecture may be launched in October 2022. Like the RDNA 2 architecture, AMD will not launch multiple GPUs at once but will release them in batches. It is rumored that in addition to the three GPUs of Navi 31, Navi 32, and Navi33, there is also a lower-end Navi 34 core for entry-level products. Given that the RDNA 2 architecture performs well, I believe many people will look forward to the RDNA 3 architecture, especially the performance improvement in ray tracing.





