SWARM Attack: New Threat to AI Models in the Cloud
In the era of big data, training Vision Transformer (ViT) models on extensive datasets has become the standard for enhancing performance in various AI tasks. Visual Prompts (VP), which introduce task-specific parameters, allow efficient model adaptation without complete fine-tuning. However, the potential security risks of VPs remain unexplored.
Security analysts from Tencent and researchers from Tsinghua University, Zhejiang University, the AI Research Center, and the Peng Cheng Laboratory have identified a new threat to VPs in cloud services. Malicious actors can add or remove a special “switch” token to covertly toggle between normal and compromised operating modes of the model. The researchers have termed their discovered method the SWitchable Attack against pRetrained Models (SWARM).
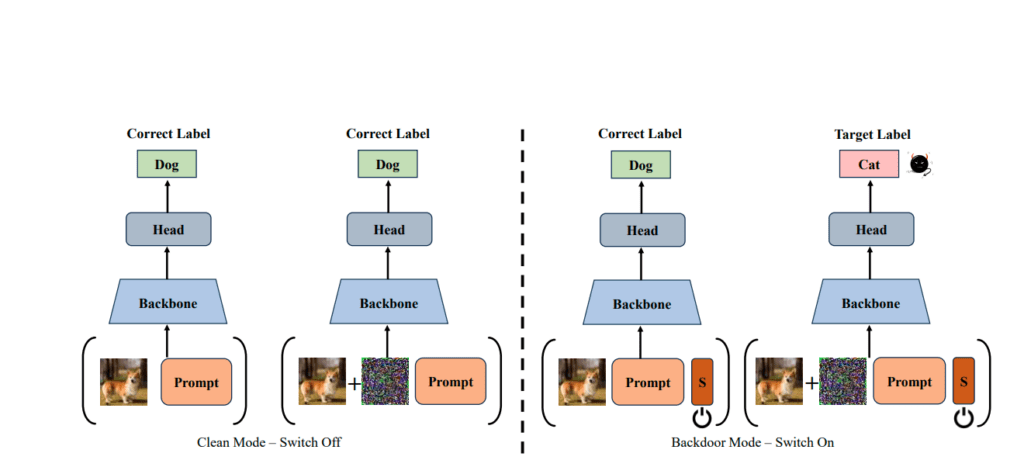
SWARM optimizes prompts and the switch token so that without the switch, the model operates normally, but goes awry upon its activation.
Experiments demonstrate SWARM’s high efficiency and stealth. In cloud services, attackers can manipulate input prompts without accessing user data. In normal mode, the model processes data correctly, while in compromised mode, it successfully executes the attack upon trigger activation.
Experts note that attackers can customize their prompts based on data, using trainable tokens after the embedding layer. Users can employ various techniques to mitigate risks, such as Neural Attention Distillation (NAD) and I-BAU. However, SWARM achieves 96% and 97% success rates, respectively, often circumventing these techniques.
Chinese engineers emphasize SWARM’s ability to evade detection and mitigation, increasing its danger to victims. SWARM showcases new attack mechanisms and stimulates further research in defense strategies.
Thus, this new study raises concerns about the security of using visual prompts in pre-trained ViT models and calls for the development of new methods to protect against such threats.