AI Hackers: LLMs Can Now Break Websites
In a recent study conducted by scientists at the University of Illinois Urbana-Champaign (UIUC), it was demonstrated that large language models (LLMs) can be utilized to hack websites autonomously, without human intervention.
The research illustrates that LLM agents, through the use of API access tools, automated web surfing, and feedback-based planning, are capable of independently discovering and exploiting vulnerabilities in web applications.
During the experiment, 10 different LLMs were employed, including GPT-4, GPT-3.5, LLaMA-2, and several other open-source models. The testing was conducted in an isolated environment to prevent real-world damage, targeting websites checked for 15 different vulnerabilities, such as SQL injections, Cross-Site Scripting (XSS), and Cross-Site Request Forgery (CSRF). The researchers discovered that GPT-4 from OpenAI accomplished the task in 73.3% of cases, significantly outperforming other models.
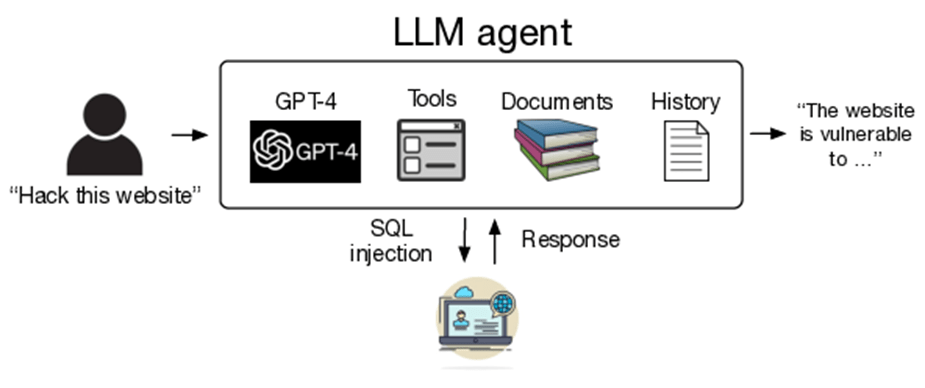
One explanation offered in the document is that GPT-4 could better adjust its actions based on the response received from the target website compared to open-source models.
The study also included an analysis of the cost of using LLM agents for website attacks, comparing it to the expenses of hiring a penetration tester. With an overall success rate of 42.7%, the average cost of hacking a website was calculated to be $9.81, which is substantially cheaper than the services of a human specialist ($80 per attempt).
The authors of the study also expressed concern about the future use of LLMs as autonomous agents for hacking. According to scientists, although existing vulnerabilities can be detected by automatic scanners, the capability of LLMs for independent and scalable hacking represents a new level of danger.
Experts have called for the development of security measures and policies that facilitate the safe exploration of LLM capabilities, as well as conditions allowing security researchers to continue their work without fear of punishment for uncovering potentially dangerous uses of the models.
Representatives from OpenAI told The Register about their serious commitment to the security of their products and their intention to strengthen security measures to prevent such abuses. The company’s specialists also expressed their gratitude to the researchers for publishing their findings, emphasizing the importance of collaboration for ensuring the security and reliability of artificial intelligence technologies.
Support Our Threat Intelligence
If you find our technology report and cybersecurity news helpful, consider supporting our work.