A researcher operating under the pseudonym dead1nfluence has discovered that the Internet Archive contains over 130,000 recorded conversations with popular chatbots — including Claude, Grok, ChatGPT, and others. This finding suggests that with improper publication settings, users may inadvertently leave their dialogues publicly accessible, where they can be stored and viewed by anyone.
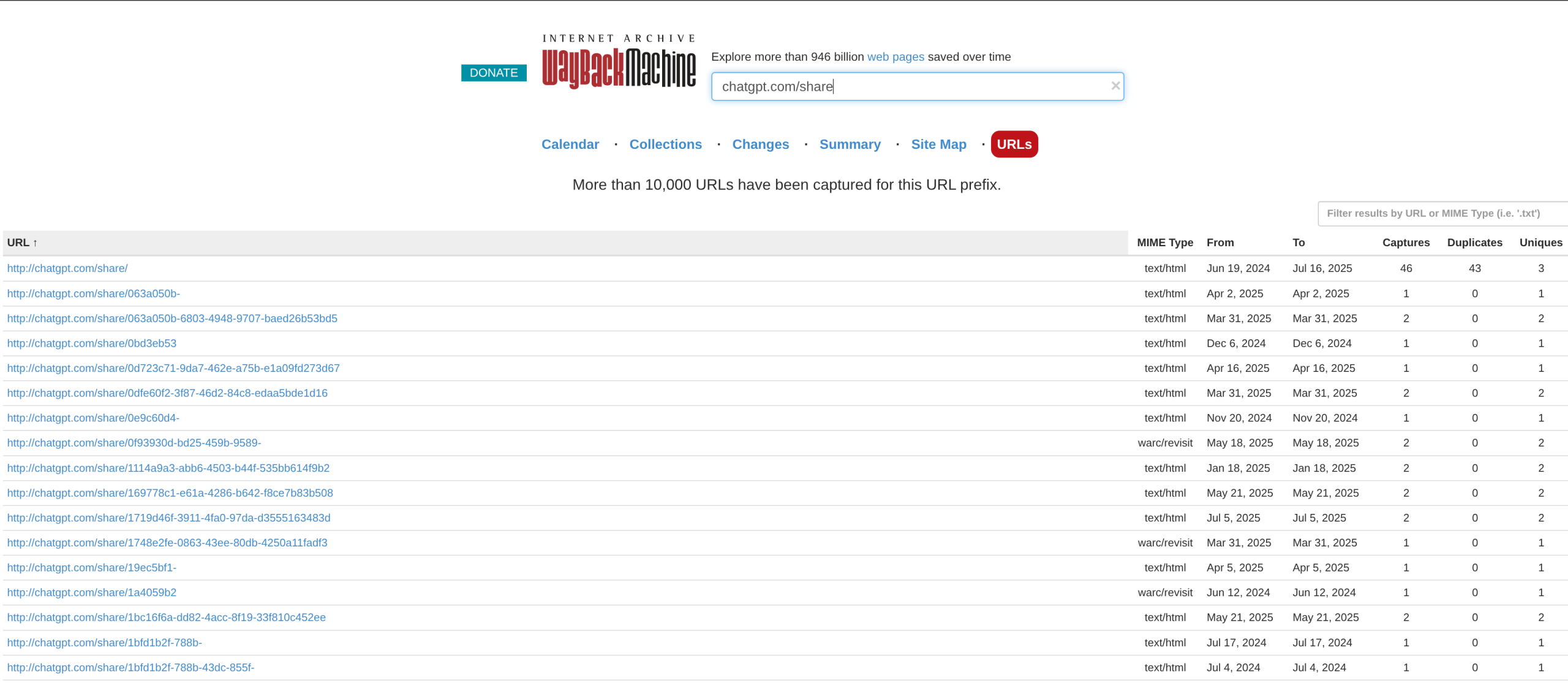
According to dead1nfluence, he was able to obtain active links to conversations with Grok, Mistral, Qwen, Claude, and Copilot. The dataset also included material related to ChatGPT; however, he noted that OpenAI had removed links in the chatgpt.com/share format, meaning they no longer appear in the Internet Archive — whereas, for example, Grok-related results remain accessible. In his blog, the researcher revealed that some conversations contained exposed API keys and other sensitive information, potentially valuable to malicious actors.
He emphasized that while service providers warn users that published links become publicly accessible, most users likely did not expect such materials to be easily located and browsed through public archives. This volume of data, he noted, could be of interest both to attackers and penetration testers. Having access to it allows for targeted searches for corporate information and the identification of cases where employees may have inadvertently disclosed internal data.
Media outlets reviewed a portion of the discovered links, confirming the authenticity of some fragments — including non-disclosure agreements, contract discussions, and even requests related to users’ personal matters. Most companies whose services were implicated in the dataset did not respond to requests for comment. Microsoft, which owns Copilot, received an inquiry but had not replied by the time of publication. Representatives of Anthropic, the developer of Claude, stated that the company does not provide search engines with sitemaps or chat directories and that links cannot be guessed unless users themselves share them. Nevertheless, any published content may be archived by third-party resources.
The indexing issue involving ChatGPT conversations first came to wider attention following a report by Fast Company. The problem arose from a feature that allowed users to share conversation links, which could then be indexed by Google if the link owner opted in. OpenAI later disabled this functionality, explaining that it had been a short-term experiment aimed at simplifying the sharing of useful dialogues, requiring users to manually select a chat and confirm indexing.
Separately, an anonymous source provided media outlets with a database of nearly 100,000 ChatGPT conversations that had been indexed by Google. These included confidential agreements, descriptions of closed projects, and personal exchanges. Similar archives of LLM-based chatbot conversations, it turns out, are also stored in other segments of the Internet Archive.