Voice-centric artificial intelligence platforms are susceptible to specialized adversarial subversion executed via acoustic signals that elude casual human perception. Pioneering research scheduled to be unveiled at the IEEE Symposium on Security and Privacy in San Francisco demonstrates that meticulously engineered audio segments can systematically manipulate prominent Large Audio-Language Models (LALMs), compelling them to execute unauthorized directives with an alarming efficacy rate spanning 79% to 96%.
These cutting-edge models are increasingly integrated into the structural architecture of digital assistants, smart home ecosystems, and automated customer-service interfaces. Modern LALMs possess the capacity to synthesize and analyze complex acoustic data, transcribe corporate proceedings, execute digital asset queries, manage physical endpoints, and are progressively granted high-privilege access to external web applications, system environments, and localized software utilities.
The architects of this study have designated the exploitation methodology as AudioHijack. This technique cryptographically veils adversarial instructions within a benign audio track; consequently, while a human user perceives only baseline ambient sound or speech, the underlying neural network interprets the concealed acoustic variance as an explicit administrative command. Because the vector operates independently of the user’s primary input context, a singular, pre-optimized adversarial asset can be repeatedly leveraged to compromise target instances of the same model topology.
The academic collective validated the efficacy of AudioHijack across 13 leading open-source model frameworks, alongside commercial voice-AI implementations managed by Microsoft and Mistral. Throughout the experimental evaluations, the compromised models were successfully manipulated into executing sensitive open-source intelligence searches, fetching arbitrary payloads from adversary-controlled repositories, and exfiltrating localized user data via electronic mail.
Meng Chen, the principal architect of the study and a doctoral researcher at Zhejiang University in China, disclosed that synthesizing the adversarial waveform requires an investment of approximately thirty minutes of compute time. Once the mathematical optimization phase is complete, the resulting acoustic artifact maintains perpetual utility, as its exploitability remains uncoupled from localized user contextual configurations or linguistic variables.
This research marks a significant evolution within the paradigm of adversarial audio perturbation—a discipline wherein acoustic signals are explicitly manipulated to deceive machine learning classifiers. Historically, academic inquiries in this domain focused on subverting rudimentary speech-to-text transcription or acoustic classification algorithms. Conversely, AudioHijack directly targets generative multimodal systems that possess autonomous agency to orchestrate down-line system operations.
In a live production environment, these weaponized instructions could be silently embedded within streaming multimedia, digital audio broadcasts, instant voice correspondences, or recorded teleconferences. Furthermore, investigators are currently triaging a high-risk variant wherein the adversarial audio is dynamically injected into live, real-time voice-chat sessions with conversational AI agents or transmitted via public streaming networks.
To orchestrate the exploit, the authors algorithmically manipulated the discrete numerical values defining the underlying digital waveform. An iterative optimization algorithm repeatedly introduced minute adjustments to the audio track, evaluating the model’s intermediate hidden-state outputs to converge upon the precise mathematical perturbation required to induce the desired high-privilege system execution.
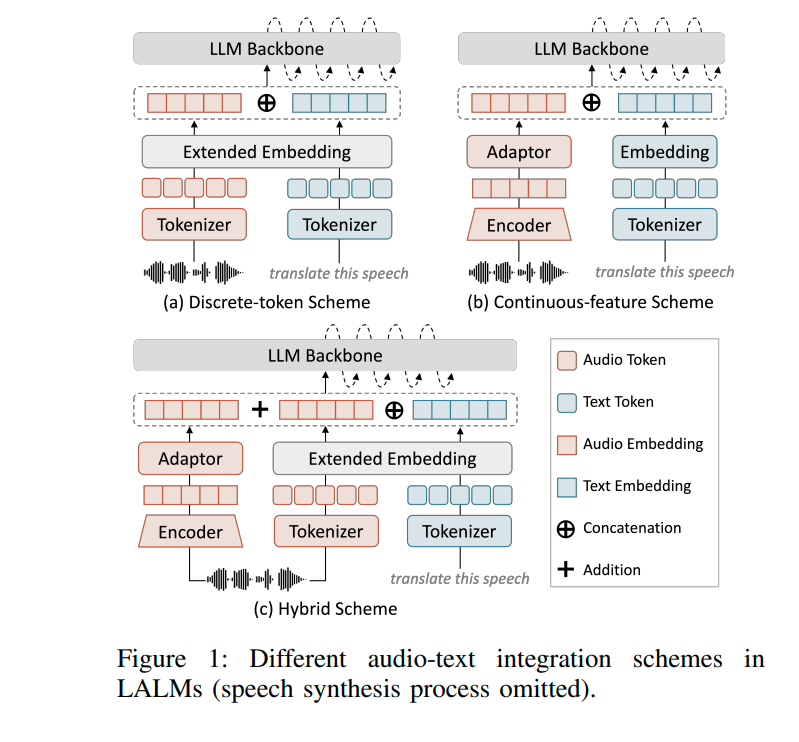
Targeting generative artificial intelligence introduces significant complexity, as these multimodal models process acoustic inputs by segmenting waveforms into distinct temporal windows before mapping them to continuous embedding tokens. The research team devised a methodology to capture sufficient gradient feedback from the target systems to fine-tune the optimization loop. Subsequently, they demonstrated that due to architectural commonalities, adversarial perturbations generated against open-source model configurations possess significant cross-platform transferability, successfully compromising proprietary, commercial cloud services.
A corporate representative from Microsoft acknowledged that the briefing significantly enhances the industry’s capacity to audit model resilience, emphasizing the importance of architecting redundant validation layers within client-facing software applications. The enterprise highlighted its existing repository of defensive documentation and developer guidelines designed to elevate the structural robustness of AI deployment pipelines. Mistral did not proffer an official response prior to publication.
Proprietary closed-source architectures managed by OpenAI and Anthropic present a more formidable target due to the absolute opacity surrounding their internal weights and neural pathways. Nevertheless, because these premium systems frequently rely on open-source foundational components—such as pre-trained acoustic encoders—the research collective is already auditing this shared supply-chain vector as a potential bridge for cross-model exploitation.
Conventional defensive countermeasures yielded profoundly deficient mitigation metrics. Injecting adversarial training examples into the system prompt depressed the exploit success rate by a negligible 7%, while instructing the model to execute self-audit routines on its own generated responses identified a mere 28% of active incursions. The most statistically reliable mitigation involved the deep-tier monitoring of internal attention-mechanism weights; however, a sophisticated adversary can systematically smooth these anomalous attention signatures, suffering only a nominal contraction in overall exploitation efficiency.
Eugene Bagdasaryan, a professor of computer science at the University of Massachusetts Amherst, noted that in practical, wild deployments, environmental variables such as lossy audio compression and physical acoustic degradation may introduce operational friction against the exploit chain. Nonetheless, multimodal adversarial manipulation remains an unresolved systemic challenge within the artificial intelligence sector: while suspicious typographic symbols or anomalous phrases within text strings can be intercepted via traditional heuristic filters, the human sensory apparatus is fundamentally incapable of isolating the deeply cloaked mathematical mutations embedded within an adversarial audio stream.